


Although many human activities damage environments and pose risks to species conservation, traditional ecological knowledge can be an important source of alternative knowledge for resource conservation when considered in ecological studies. Conservation actions are inefficient when the needs and suggestions of local populations are disregarded in conservation decision making and doing so often generates social-environmental conflicts. In addition, the lack of dialogue between ecologists, managing entities, and local populations has increased the challenges associated with the conservation of diverse natural resources in a various ecosystems and has resulted in many species being threatened with local extinction. In this article, we emphasize local ecological knowledge (LEK) as an emergent property of social-ecological systems and demonstrate that it is necessary to consider LEK in ecological conservation studies. In addition, we discuss the challenges and limitations that can arise in conservation-oriented ecological studies, with an emphasis on establishing good rapport with local communities. Science has a great responsibility to find viable alternatives in order to circumvent social-environmental conflicts. Thus, if the goal of academics and managing entities is biological conservation while safeguarding the needs of local populations, knowledge and natural resource management suggestions from local communities must be considered in order to minimize conflict.
The quest for understanding ecological phenomena and processes should not ignore the effects of the dominant species on the planet: Homo sapiens. Human populations have severely altered the environment since human prehistory (Johnson, 2009), directly and indirectly impacting the populations of numerous species and the environment as a whole (Ceballos et al., 2017). It is estimated that more than three quarters of the terrestrial surface has been converted to anthropogenic zones for the primary purposes of agriculture and livestock production, which has lead researchers to propose the term anthrome to reflect the anthropogenic influence on existing biomes (Fig. 1; Ellis and Ramankutty, 2008). In addition, humans have influenced a wide range of biological processes, such as domestication, the direct genetic modification of organisms, the use of fossil fuels, the chemical and biological control of other species, and energy production from different natural sources (Ellis, 2015).
 we propose be taken into account when designing conservation measures, analyzing degradation processes, or evaluating biological conservation outcomes. In addition, local populations can act in the management and co-management of natural resources. The involvement of local populations, decision makers, and researchers in conservation decision-making is important for the creation of restoration zones, which are essential for generating change in the anthrome that borders rural populations. Brown color and lines represent the area to be restored.")
Protected or preserved areas and areas adjoining rural populations. The rural populations represent those people whose local ecological knowledge (LEK) we propose be taken into account when designing conservation measures, analyzing degradation processes, or evaluating biological conservation outcomes. In addition, local populations can act in the management and co-management of natural resources. The involvement of local populations, decision makers, and researchers in conservation decision-making is important for the creation of restoration zones, which are essential for generating change in the anthrome that borders rural populations. Brown color and lines represent the area to be restored.
Therefore, the ecological processes that structure biological diversity and ecosystem functions occur in a world that has been completely altered by human action. Hence, ecologists must understand how human activities can influence these processes, how promptly species respond to these activities, and how these activities affect the dynamics of human-resource relationships given the changes that occur in ecosystems and consequently the availability of resources. The evaluation of these complex relationships represents an enormous challenge and involves temporal assessments to understand changes in social-ecological systems at local, regional, and global scales (Sutherland et al., 2013). Nonetheless, these evaluations will make it possible to highlight measures that favor the conservation of biodiversity and the sustainability of future human activities. Considering that most ecological studies are restricted to short-term observations, access to the knowledge of human groups with regard to their environments can amplify this temporal scale as this knowledge has been formed by observations and perceptions of biota over a much longer period of time (Boillat and Berkes, 2013; Berkes et al., 1995). In the absence of data that traces aspects of the past, such as the abundance of certain species, this knowledge can thus provide us with important information for the purposes of ecological inference.
In addition, human populations whose local management systems have considerably contributed to the current levels of biodiversity (Berkes et al., 1995) have historically managed the largest proportions of biodiversity. An emblematic example of this statement can be found in the study conducted by Levis et al. (2017) in the Amazon Forest. This study found that the domestication of plant species by pre-Columbian societies had a strong influence on the structure and composition of the modern forest. Currently, indigenous groups and local communities are involved in the management of many protected areas worldwide, particularly in South America and Oceania (Deguignet et al., 2014). This type of evidence refutes the idea of untouched ecosystems and indicates the need to include the human factor when attempting to understand ecological processes and landscape structures in different ecosystems (Balée, 1989; Balée, 1992).
It has been observed that studies in ecology and conservation are still conducted with a unilateral and negative view of human interference as it relates to biodiversity (see Albuquerque et al., 2018; 2019a). This view neglects that anthropic interference can also act to increase species diversity and abundance (Voeks, 1996; Toledo and Salick, 2006). This view is due to complex contemporary issues, such as the cumulative decline of forest areas, global climate change, the accelerated reduction in population size of multiple taxa, and the prospect of a new mass extinction event already under way (Barnosky et al., 2011; Ceballos et al., 2017).
Thus, the design of protected areas has emerged as a reflection of this context, creating a dichotomy between human beings and nature while assuming that the best way to promote the conservation of biodiversity is to isolate it from the human element (see Arruda, 1999; Bettina et al., 2018; Watson et al., 2014). This conceptualization of a nature as isolated from the anthropic element permeates the main conservation models that have been adopted by the governments of different countries. Although protected areas play an important role in the conservation of nature, human populations are often neglected in their design and implementation (Struhsaker et al., 2005). As a result, a series of social and cultural conflicts have come into existence when the people who live in these areas have had no say in the management decisions of these areas (Diegues, 2000; Andrade et al., 2015; Andrade, 2016). This lack of participation often results in the failure of these conservation models. The resulting scenario is problematic and challenging since the areas of the globe that are considered conservation priorities (hotspots) harbor large portions of the human population, including traditional populations (Hanazaki, 2003).
The absence or low participation of communities in the decision-making process, combined with the criminalization of traditional practices (such as hunting, fishing, and plant use) and the insecurity in local populations, generates a number of undesirable effects. In some cases, criminal community members have been found to perceive protected forests as landfills, as places to dispose of corpses, or as places to hide from the authorities (Bento-Silva et al., 2015). Other undesirable effects also include a decrease in the quality of life of local populations and a consequent increase in poverty, a disregard for conservation actions, rural exodus, environmental degradation caused by new housing developments, and the overexploitation of accessible areas (Arruda, 1999; West et al., 2006). For example, in conservation areas of the Raso da Catarina region in Brazil, the endemic Lear’s Macaw (Anodorhynchus leari) has left the protected forests to feed on crops, which has negatively impacted agricultural production. Conservation measures prevent action rural communities against A. leari. Nevertheless, numerous individuals have claimed that they have become angry with the species and have taking actions to kill or increase the risk of A. leari being captured for illegal trade, such as throwing hard objects or fireworks at the birds (Andrade, 2016).
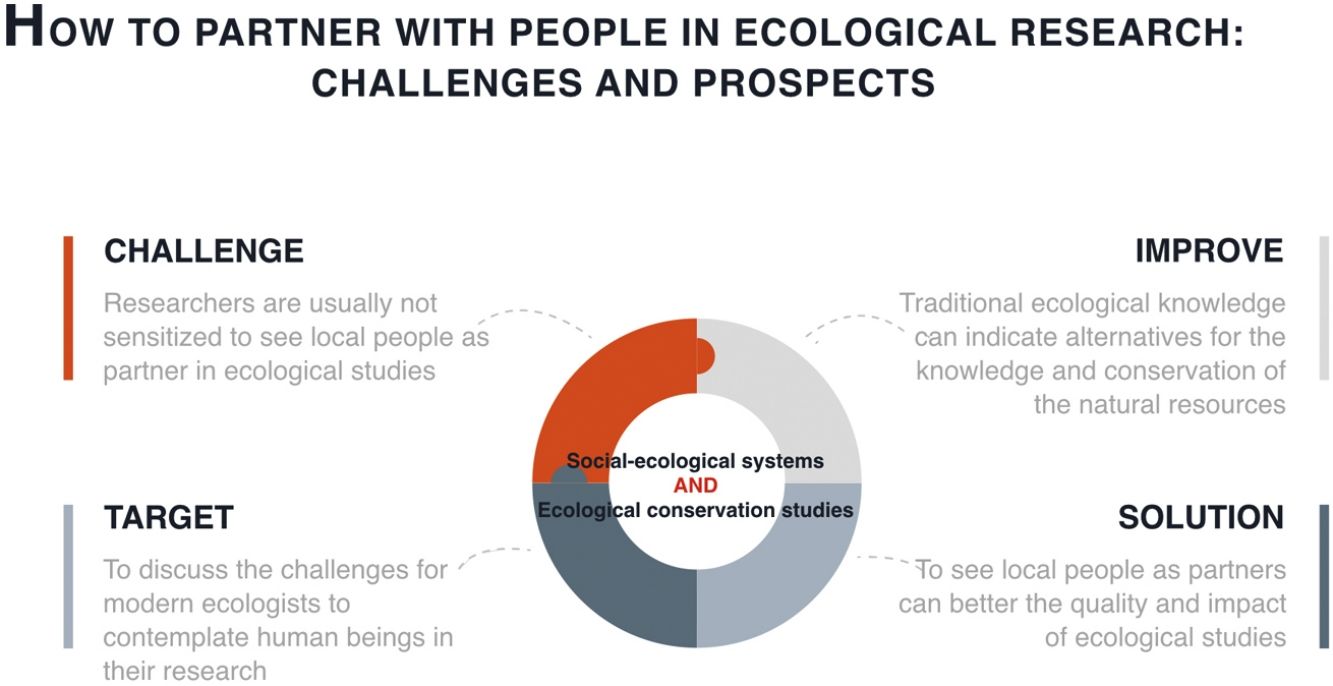
Therefore, the social and environmental problems that have arisen with the establishment of conservation measures need to be considered and evaluated. Although the environmental crisis needs to be confronted, people have the right to property and the material conditions that are indispensable to a life with dignity (see Articles 17 and 22 of the Universal Declaration of Human Rights, UN General Assembly, 1948). Undoubtedly, working in the context of socio-environmental conflicts imposes a series of ethical and methodological challenges for ecologists that can sometimes compromise the quality and reliability of the data being collected. As researchers are usually not sensitized to these issues, this source of research bias goes unnoticed. In this article, we discuss the challenges faced by modern ecologists when contemplating human beings in the context of their research. This challenge does not imply necessarily having to research people, but rather to consider their influence on the ecological processes under investigation. Most of the ideas that we are presenting agree with what is being developed by the Intergovernmental Science-Policy Platform on Biodiversity and Ecosystem Services (IPBES - https://www.ipbes.net).
Emerging properties of human-environment relationshipsThe ecological literature has conceived an ecosystem view that considers humans as an external element to natural systems, and people are usually seen as disturbing agents that generate negative ecosystem impacts. However, humans can be seen as an integral part of nature, and their interactions with the environment are generally more complex than the interactions of other animals as humans which are mostly self-conscious, cooperative, technological, and highly social beings (Sutton and Anderson, 2010). For example, thousands of people throughout the world have their subsistence needs met by the collection of forest products (Cavalcanti et al., 2015; Ticktin, 2004). As local the communities are economically dependent on these resources, plant species management has become one of their most successful practices. Sustainable collection is not only important for the subsistence of these human populations but is also important for plant species (Ticktin, 2004). Therefore, information regarding local species knowledge and uses are important to infer the potential impacts of this practice on the relationships between the members of different plant populations (Gaoue et al., 2011, 2013; Gaoue and Ticktin, 2007; Feitosa et al., 2017, 2018). It is common practice for ecological studies to analyze multiple aspects related to plant species while not employing methods to investigate the human components in the relationships they study.
More recently, a complex view of the interactions between humans and the environment has been proposed with the accompanying term social-ecological system, which refers to a system that encompasses both the biophysical and social systems present (Berkes and Folke, 1998). Social-ecological systems are complex and dynamic, and their characteristics change over time in response to various factors, such as socioeconomic and environmental changes (Alessa et al., 2009; Virapongse et al., 2016; Fischer, 2018). With the introduction of social-ecological systems, views on interactions between humans and the environment must be restructured and thus it is possible to recognize and describe certain properties that emerge from these interactions. Local ecological knowledge (LEK) is an inherent component of social-ecological systems. Usually, LEK is defined as a cumulative body of knowledge, practices, and beliefs developed by humans in their relationships with other living beings, with each other, and with the environment (Berkes et al., 2000; Berkes, 2018). Local ecological knowledge is a cultural oral tradition that is transmitted through shared experiences and practices. Although LEK is essential for the existence of social-ecological systems given that humans generate knowledge about their environments to manage natural resources, it can also be understood as an emergent property of this social-ecological system since its existence is based on the interrelationships between people and their environments.
Local ecological knowledge plays a key role that guides the way in which social-ecological systems respond to environmental (Fernandez-Llamazares et al., 2015) and sociocultural disturbances (Peneque-Gálvez et al., 2018). For example, LEK may guide responses to recent changes in climate, modifying human strategies with regard to their interactions with the environment (Leonard et al., 2013; Makondo and Thomas, 2018). In particular, LEK has favored changes in the types of species that are cultivated by farmers (Rufino et al., 2013; Makondo and Thomas, 2018). The Miriwung people in Australia have responded to climate change by enabling resource sharing between their communities and fire management entities. This knowledge is important in the region because it facilitates traditional hunting practices and decreases the chance of intense fires in the future (Leonard et al., 2013).
Since the development of LEK throughout human evolution, human groups have presented environmental interactions that are in many ways equivalent to widely recognized concepts in ecology. For example, humans exert pressures on natural systems during the collection and use of natural resources, which may be considered analogous to some of the interactions studied in ecology, such as predation, competition, and commensalism. However, few ecological studies use this perspective to view human-environment interactions in the same manner as the ecological processes of other species. In a modeling study of the effects of hunting by the Matsigenka people on populations of the spider monkey Ateles chamek Humboldt in the Amazonian forest (Levi et al., 2009), the authors simulated the effects of Matsigenka population growth, possible migrations to new areas, and the replacement of traditional bow and arrow hunting with firearms. From these simulations, it was concluded that firearm hunting would pose a great threat to the local population of spider monkeys by the creation of large defaunation areas due to increased hunting efficiency. Another interesting example of the effects of human practices on other species involves the construction of landscapes of fear as a result of predation by human groups. A study monitored 35 brown bears (Ursus arctos) in Sweden during 2012–2015 and assessed individual foraging patterns in different areas, which varied according to food availability (i.e., Vaccinium myrtillus L. fruits) and the risk of hunting by human groups (Lodberg-Holm et al., 2019). The authors observed that bears preferentially selected areas with high food availability and low hunting risk. In addition, the bears killed during the study period had visited areas mainly based on food availability and not on the risk of hunting (Lodberg-Holm et al., 2019). In this case, human actions may have led to changes in bear foraging behavior as the bears had to consider and perceive the risk of predation during the search for food (Lodberg-Holm et al., 2019; Gaynor et al., 2019).
Other human actions do not result in direct effects but have cascading effects on ecological interactions. In Karimunjawa National Park, Indonesia, traditional fishing seems to have caused cascade changes in reef communities. The different fishing techniques employed in the region have possibly reduced carnivorous fish stocks and consequently increased the density of herbivorous fish, especially those of the families Scaridade and Pomacanthidae. These herbivorous fish are thought to consume late successional species of algae and thus promote the growth of fast-growing turf algae species, which outcompete corals (Campbell and Pardede, 2006). The complexity of the direct and indirect effects of human actions on biodiversity can be observed by considering another emerging property of social-ecological systems. This property is linked with the complex interaction webs of biocultural keystone species. However, there are different biocultural keystone species concepts. Shackleton et al. (2018) consider biocultural keystone species to be those whose influence in a community is disproportionately high when compared to their local abundance and who are of great ecological and cultural importance and influence the identity of people. Shackleton et al. (2018) exemplify this concept based on the published information of the buriti palm (Mauritia flexuosa L.), an ecologically and culturally relevant species in central and western Brazil. Local human populations target this species to collect its fruits. The fruits are also consumed by a wide range of mammals, reptiles, and birds, which act as seed dispersers. In addition, some mammalian species that act as buriti seed dispersers are hunted for domestic consumption. Therefore, the buriti palm is at the center of a complex web of social-ecological interactions, in which extractivism can affect the population structure of the palm itself as well as that of the other animals that consume its fruits (Shackleton et al., 2018).
Given the effects that humans can provoke through the use of certain species and landscapes, it is essential to evaluate the factors that influence human environmental practices. Thus, LEK investigations are important in evaluating human decisions related to species and landscape management in order to understand the human motives and preferences that lead to the transformation of natural spaces. A particular example can be found among the Tsimané people in the Bolivian Amazon. Tsimané villages with inhabitants that possess a greater knowledge of local plant use are surrounded by forests in higher conservation states and in which smaller forest areas have been cleared for agricultural purposes. One possible interpretation is that villages that have a greater knowledge of plants may have people who deal more frequently with the environment and strongly depend on its natural resources, such as foragers or experienced farmers, which decreases forest-cutting actions (Paneque-Gálvez et al., 2018). In addition, in these villages, people with higher levels of LEK may present beliefs related to the presence of spirits in the forest (e.g., spirits in water sources or in certain trees), which prevents people from collecting resources in certain areas (Paneque-Gálvez et al., 2018).
An important case that reveals the reasons behind certain anthropogenic actions in the environment is related to the domestication of species and landscapes throughout the biological and cultural evolution of humans (Watling et al., 2018). Humans have differentially selected and manipulated species or variants in order to favor a set of preferred characteristics and to discourage unwanted characteristics (Chen et al., 2018; Che and Zhang, 2019). A study conducted in seven communities in Mexico showed that larger fruits are found in domesticated varieties of Crescentia cujete, the calabash tree, when compared to wild varieties (Aguirre-Dugua et al., 2013). The fruits of this species are mainly used in communities to prepare pots, and people prefer larger fruits with thick pericarps to produce larger and sturdier bowls (Aguirre-Dugua et al., 2013). In another study, Casas and Caballero (1996) showed that people living in the Mixtec region of Mexico identified three types of guaje (Leucaena esculenta subsp. esculenta) as being either (1) guaje dulce, which is not bitter and suitable for consumption; (2) guaje amargo, which has bitter pods and is only suitable for consumption when roasted; or (3) guaje de vasca, which presents toxic compounds and is not suitable for consumption. The authors noted that people manipulated disturbed areas to eliminate the amargo and de vasca varieties while keeping dulce individuals. Over time, this kind of differential management can modify landscapes and generate persistent environmental effects (Levis et al., 2017; Sullivan et al., 2017; Watling et al., 2018).
Despite studies that demonstrate that indigenous peoples and local communities may contribute valuable species conservation knowledge (Ulicsni et al., 2019), researchers often focus their studies to understand only the ecological aspects of a given environment, without considering the influence that people exert on the conservation and use of resources found within. In part, this is due to a lack of preparation and experience on the part of the researchers with regard to LEK, making them reluctant to include LEK in their research (Ulicsni et al., 2019). Understanding human effects can increases the explanatory capacity of ecological processes and can facilitate the implementation of conservation policies that are more suitable to local realities while decreasing the risk of conflict with local communities. Examples of how the combination of LEK with scientific knowledge can be important for sustainable management and management of natural resources are observed in different regions through cases of co-management (Velazquez et al., 2001; Moller et al., 2004). In Brazil we have the case of the Black Fern (Rumohra adiantiformis), where through a joint action between government agencies, researchers and the local community, a management plan was developed for species locally exploited for different purposes, which ensured the restructuring of the species ecological population and the strengthening of the local economy (Coelho de Souza et al., 2006).
Avoiding conflicts with people in ecological and conservation studiesSocial-environmental conflict can be defined as situations in which two or more social actors with strong opinions are confronted with distinct conservation objectives, or when one party promotes its interests at the expense of another (Young et al., 2010). Thus, conservation strategies will only succeed when scientists do not prioritize their interests to the detriment of others who are also interested in the natural resources in question (Redpath et al., 2013). For example, conflicts arise when conservation objectives are imposed on others without dialogue between the parties, such as when human beings are excluded from protected areas (Redpath et al., 2013) or when supervisory bodies restrict the use of a particular natural resource (to better understand the factors influencing socio-environmental conflicts see Hossu et al., 2018).
Many challenges are imposed on researchers pursuing the development of conservation studies in conflict situations. These challenges may involve creating strategies to mitigate the effects that may arise from their studies or from other pre-existing conflicts. From this perspective, science can facilitate the negotiation of environmental decisions and can mediate the dialogue among the multiple spheres involved in an environmental conflict. In this sense, the effort to incorporate LEK into environmental management processes has become a conservation initiative in several countries (Sobral et al., 2017).
In addition to contributing to conservation and environmental management research, ecological studies that seek to understand the mechanisms and dynamics that are linked to the environment can also benefit from the incorporation of LEK (Fig. 1). In this sense, ecological studies are often executed in regions where human populations are settled and depend to a greater or lesser degree on resources to maintain their way of life. In addition, humans tend to construct bodies of knowledge regarding the broad ecological aspects of the regions in which they live, such as knowledge related to climate change factors, species population dynamics, or phenological patterns (see Silva et al., 2017; Sobral et al., 2017; Ulicsni et al., 2019). This information is important and may be used to direct ecological studies in these regions. Local ecological knowledge can provide insight into the impacts and transformations that the study areas may have experienced over time, which is particularly important for assessing how anthropogenic actions affect biodiversity. From a practical perspective, the results of these studies may allow for a dialogue between ecologists, decision makers, and managers that promotes biodiversity and favors conservation (Bonari et al., 2019). However, it is a challenge to conduct ecological studies, especially in areas under environmental protection where people live with laws aimed to protect natural resources (see Andrade, 2016; Newmark et al., 1994; Nepal and Weber, 1995; Redpath et al., 2013).
Redpath et al. (2013) provide an example that illustrates this scenario. In the UK, a conflict exists that involves seals and salmon fishing and that comprises various social groups. According to the authors, this situation is a reflection of the impact that seals have on salmon fisheries and salmon population dynamics as perceived by the local fishers. This conflict manifests as perceived effects related to fishing productivity. Fishers perceive seals as the agents that are primarily responsible for reducing the salmon population and damaging their fishing gear. However, scientists have analyzed stomach contents, living tissues, and fecal samples collected from seals in regions close to the fishing sites and have found that salmon comprises a small proportion of the diets of those seals. According to this analysis, the effect of seal predation on salmon fishing remains uncertain. However, this uncertainty has added to the existing perception that seals are salmon predators and has led fishers to slaughter seals, which has resulted in the rise of greater problems. In response to this situation, a scientist from the Salmon Fishery Board developed a management plan that involved all stakeholders, including ecologists and fishers, that demanded commitment from all parties, and considered the interests of all parties involved. This plan motivated the Scottish government to issue annual salmon fishing licenses that are based on population estimates from ecologists that provide guidelines for sustainable fishing. As a result, fishers have reduced the slaughter of seals and maintained their fishing practices within the limits established by the government (Redpath et al., 2013).
Some ecological studies worldwide occur in areas marked by strong socio-environmental conflicts, as in the conservation units of Brazil. These studies may or may not be seeking to understand the effects of human actions on ecological processes (see Sfair et al., 2018; Siqueira et al., 2018). Thus, it is very common for researchers to focus on their research problem while neglecting existing sociocultural dynamics, which may even affect their own research outcomes. An example of this is the lack of trust between researchers, and local leaders when explaining the purpose of the research. This situation can lead to serious implications, such as problems with data collection, since residents may place barriers on research if they are confused with regard to the purpose of the study or if they associate researchers with managers or enforcement agents and consequently restrict the use of the study areas (in which there may already have been previous conflicts). In addition, scientists that do not consider social and environmental conflicts may be perceived by local populations to be biased because the scientists are perceived to defend only their research interests (see Redpath et al., 2013).
Conflicts such as these occur in all habitats and can drastically affect local socioeconomic and biological parameters (Young et al., 2010). In ecological studies in particular, scientists are faced with problems that arise from these conflicts and must resort to strategies to circumvent these problems so as not to affect their field work and the conclusions that stem from it. However, if the aforementioned factors are not considered, circumventing such conflicts may be impossible.
Collecting data for ecological studies with local peopleSometimes ecological studies need to collect data directly from local people for different purposes (see, for example, Arnan et al., 2018). Although there are manuals that are dedicated to the established procedures for approaching and collecting data from human populations (see Albuquerque et al., 2014, 2019b), it is necessary to consider that LEK, like any other ecological variable, varies within a single population. Therefore, it is essential to compose population samples effectively to better acquire and understand LEK.
Considering direct and indirect anthropogenic effects in ecological studies presents challenges that transcend the ecological methods of the study. First, in order to work directly with people, all ethical and legal prerequisites must be met. Legal procedures for accessing local knowledge will depend on the applicable laws of each country. However, obtaining informed consent (IC) from participants is a general rule (Parry and Mauthner, 2004). This IC is the authorization given by the research participants to participate in data collection (either individually or collectively) and for the subsequent publication of the data (Allmark et al., 2009). Confidentiality ensures that participants will not be publicly identified in connection with the reported data (Clark and Sharf, 2007). However, informant privacy may prevent them from saying something that they or another member of the community would prefer to remain secret or that could potentially cause harm (Allmark et al., 2009).
In addition to the need to obtain the individual consent of the participants, recognizing the social structure of the community is vital to properly carry out research activities (Treves et al., 2006). Talking with local leaders and requesting their authorization for the development of the research can open doors for the researcher and is ethical. This facilitation can take the form of (1) easing interactions with other residents, even if they are resistant to sharing their knowledge with unknown individuals; (2) being able to count on the collaboration of the local population to select and access the ecological areas of particular importance for the study; and (3) making sure that long-term monitoring studies (e.g., zoological inventories with trap cameras, seed rain collection, or fixed plots to monitor plant population dynamics) will not be contaminated or removed. In fact, when a researcher does not develop good relationships with local communities, their data may become biased in diverse ways, such as through manipulation of experiment by local people.
People also socially organize themselves in different ways, which further adds to the complexities involved in working with local communities. For example, in some patriarchal societies, women are not allowed to speak to men who are not their husbands and may only do so when authorized by their husbands (Oakley, 1998). Failure to comply with these social norms may not only alienate researchers and the person from whom they wish to obtain information but the community as a whole. This can have serious consequences, from interference in ongoing studies (e.g. plot trampling and trap removal) to extreme cases in which the researcher needs to terminate their activities in the region.
In many societies certain subjects considered taboos that should not be commented on by individuals in the community or that should not be commented on by people from outside the community (Colding and Folke, 2001). The Fulni-ô indigenous people of northeastern Brazil are a good example of this. The Fulni-ô have a traditional ritual that lasts three months, in which they isolate themselves from people of different ethnicity from themselves in a village surrounded by Caatinga vegetation (Soldati and Albuquerque, 2012). Details on how this sacred ritual is performed and access to the forest regions attached to the village are not shared with non-indigenous people (Soldati and Albuquerque, 2012).
The researcher should be sensitive to the small social and cultural nuances of a given locality. In order to do so, it is necessary to have a good preliminary knowledge of the field, an initial contact with local leaders, and a constant but non-invasive observation of local practices. These factors are essential because even small details, such as facial expressions, may have different interpretations among different populations (Dailey et al., 2010). If we consider that the success of the research may depend on the willingness of people to contribute, such attention is essential. Much more than ensuring an ethical attitude of privacy and confidentiality towards research participants, the scientist must establish a relationship of trust with local people through rapport (Springwood and King, 2001).
The aforementioned challenges can be minimized with good rapport, which is the strategy adopted by researchers to approach the people involved in their research and thus obtain reliable information (Albuquerque et al., 2014; Bernard, 2006). Although it is seen as a technique used only by researchers of the social sciences, rapport is useful in any investigation that involves direct contact with people. In addition, ecological studies generally do not require the researcher remain in the field for extended period of time. If human populations reside in the vicinity of areas where ecological data collection takes place, keeping in touch with people can ensure that the data collected does not suffer from the undesirable interferences that have been previously mentioned.
Frequently, field manuals describe rapport as a series of techniques used by the researcher to access information of interest. This type of literature describes the most adequate body posture, the way of looking, the tone of voice, the most appropriate expression (smile) or simulation of expressions, such as surprise, or even a certain ingenuity to ensure efficient rapport (see Duncombe and Jessop, 2005). In spite of the clear utility of a standardized approach, particularly for less experienced researchers, the use of these techniques can sometimes be inefficient because adopting these techniques can make a researcher look impersonal or artificial. In addition, what is considered good rapport is the object of severe criticism. Often the objective of good rapport is to facilitate the collection of data through the commercialization of the relationship between researcher and the researcher given that the researcher is led to simulate emotions and create the artificiality of a false friendship.
Another style of rapport, inspired by the therapeutic interviews of Carl Rogers, proposes a closer relationship between researchers and local people (Rogers, 1951). The need to set a genuine rapport based on empathy and a sense of equality promotes a trustworthy relationship that meets the expectations of the researcher without disrespecting local people (Kvale, 2007). Although this type of rapport requires more extensive training, this approach begins from a more ethical position, since the researcher must create an equal relationship with the population by respecting its rhythm and limits. The skill required to set this kind of good rapport, includes the ability of the researchers to bridge the gap between themselves and others, while establishing an emotional boundaries between themselves and the respondents (Duncombe and Jessop, 2005).
Despite efforts to institute an honest relationships based on mutual trust, the researcher must avoid falling into the trap of extrapolating the professional relationship to a personal one and establishing friendships with the respondent, which is deemed over-rapport (Abbe and Brandon, 2014; Miller, 1952). Miller (1952) points out that this situation can be particularly problematic. For example, when the community being investigated is split into hierarchical groups, establishing over-rapport with a particular group can produce mistrust in the other groups within the community. In this situation, people who do not belong to the group with which the researcher has established over-rapport may feel uncomfortable interacting with the researcher or sharing information. In other words, establishing an exaggerated relationship with one group can lead to distrust and to situations of internal rivalry.
Although rapport is a technique that is used to guarantee the collection of reliable information, it is a mistake to suppose that the better the rapport the more reliable the information. Thus, researchers cannot assume that the information obtained from respondents with whom they have better rapport is either of better quality or more reliable than information obtained from other respondents (Miller, 1952). For example, people who fear displeasing the researcher may omit information or manipulate data because they believe the information does not match the expectations of the researcher.
Final considerationsEfforts to understand local cultures may lead scientists to a broader understanding of anthropogenic influence in certain environments (see Paneque-Gálvez et al., 2018; Ulicsni et al., 2019). By establishing themselves in one place, local people perceive ecological patterns that can go unnoticed by even the most attentive ecologists. For example, Sobral et al. (2017) found that people in the Araripe National Forest (FLONA), Brazil, who collected two species of locally important plants, Caryocar coriaceum and Himatanthus drasticus, have extensive knowledge of the ecological patterns of these species and monitor both the biological and environmental phenomena that threaten the sustainability of their collection. The authors therefore argue that using LEK can support studies that evaluate the population dynamics and conservation status of these two species. In this sense, traditional knowledge can complement scientific knowledge with regard to various environmental aspects and bring LEK closer to the academic realm (Ulicsni et al., 2019), in addition to promoting the strategies of co-management and sustainable management of natural resources (Coelho de Souza et al., 2006; Moller et al., 2004).
In addition, disregarding local populations in the elaboration of conservation strategies may be inefficient for both understanding the ecological processes present in different ecosystems and for the proposal and application of management and conservation strategies. Cooperation with local people is increasingly urgent as recent environmental changes may be reflect a planet that progressively more dominated by humans (Corlett, 2015). However, many studies do not accomplish such cooperation given that many scientists underestimate knowledge of non-academic origin and lack experience in understanding where and how LEK can be accessed and incorporated into research efforts (Ulicsni et al., 2019). It is important to understand that conservation conflicts are hardly ever fully resolved and often require conflict management strategies to mitigate the associated impacts (Redpath et al., 2013). However, failure to consider the human dimension in ecological studies or in conservation decision making can intensify existing conflicts. Thus, it is essential that scientists equalize their interests with those of the local populations and understand that their research can play a decisive role in conflict management (Redpath et al., 2013).
Incorporating LEK into ecological studies can lead to a reduction in potential conflicts between residents who use resources in protected areas and the managing entities of these areas (Sobral et al., 2017). According to Hossu et al. (2018), we need to bring together all natural resource stakeholders to negotiate solutions for critical problems in order to eliminate conflicts of interest. By considering what local people know about their environments, their needs, and their suggestions, a better approximation of academic, political, and social interests within ecological systems may be developed that has a positive effect on the conservation of biodiversity, the sustainability of local human practices, and regional development.
This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior - Brasil (CAPES), Finance Code 001, with contributions from the INCT Ethnobiology, Bioprospecting, and Nature Conservation certified by CNPq, and financial support from FACEPE (Foundation for Support to Science and Technology of the State of Pernambuco - Grant number: APQ-0562-2.01/17). We also would like to thank the CNPq and CAPES/FACEPE (PNPD program) for the post-doctoral fellowship granted to ALBN (CNPq 151518/2018-1) and ISF (CAPES/FACEPE: APQ-0700-2.05/16 and BCT-0259.22-05/17) as well as the productivity grant awarded to ELA and UPA. We are also grateful to the editor and reviewer for their important contributions, the latter also for the suggestion of Fig. 1. We are grateful to Dr. Thiago Gonçalves-Souza for his help in making the figure.

